I’m in the process of spinning up a data stack on my home servers for portfolio projects, and I thought I’d share the journey.
What Is a Data Stack, and Why Do I Need It?
A data stack is a collection of tools, technologies, and platforms that work together to manage, process, and analyze data. If you need to move data between multiple systems into a centralized location for analytics, dashboards, reporting, or other uses, you’ll quickly encounter challenges like tech debt and messy workflows.
The goal of a data stack is to be opinionated about how you move, store, and transform data—essentially defining a structured process for taking raw data and turning it into insights.
I like this diagram create by Fivetran
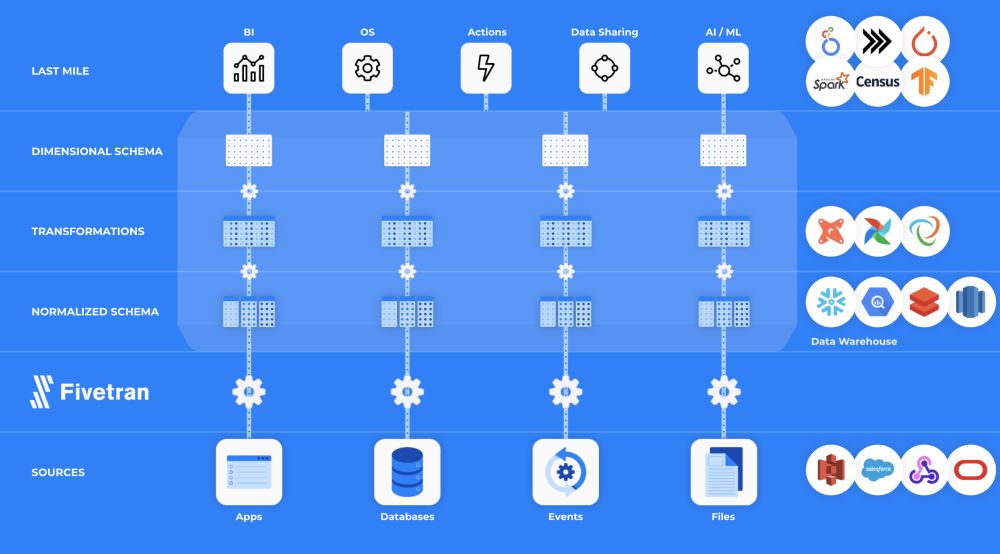
What’s so great about this?
This illustration does a fantastic job of showing how data pipelines work: moving data from its sources, through data modeling steps, to create dimensional data that’s faster and easier to use with analysis tools. In my experience, many people still perform this process manually, often referred to as data wrangling. A data stack automates data wrangling and takes it even further, unlocking possibilities for streamlined workflows, more scalable insights, alerting, observability, data democratization, the list goes on and on.
That said, there’s one aspect of this diagram that doesn’t align perfectly with how I approach things. Specifically, I view orchestration as a foundational layer rather than just a component of the transformation layer. For me, orchestration handles the entire highlighted center section—the actual process of data wrangling—not just the transformation. It’s the glue that coordinates extraction, transformation, and loading. In my data stack, orchestration is as essential as the data storage layer itself, providing the backbone for centralizing and standardizing automated workflows.
Here’s an overview of the layers I use:
1. Orchestration
Orchestration tools run the code that moves and transforms data, monitors databases, and handles other repetitive tasks. In my previous jobs, I’ve seen everything used for orchestration, from SQL Server Agent and cron jobs to… Outlook calendar reminders (manual workflows, I see you 👀).
Keeping it simple works for a while, but as the complexity grows—with more data, databases, and caching layers—it can spiral out of control.
For my stack, I’m using Apache Airflow. Here’s why I think it’s worth the learning curve:
- Scheduling: This is the core purpose—running tasks on a schedule.
- Monitoring & Visibility: Airflow’s dashboard lets you see what’s working (and what isn’t), with task logs and code visibility all in one place. This alone makes centralized orchestration tools worth the effort.
- Error Handling & Recovery: Airflow has built-in features like retry policies and failure callbacks. These help reduce the noise from transient errors, so you’re not overwhelmed by false alarms.
- Centralized Management & Collaboration: Airflow organizes your code in one place. While I don’t directly hook it to GitHub for live deployment (I like to test first), I always know where to find it.
- Python Integration: I like Python. Enough said.
- Cost: Airflow is free and open source, which works perfectly for my home lab.
2. Data Storage
Here’s where you’ll find data lakes, warehouses, and marts. For me, SQL-based relational databases are the backbone. I’ve used MSSQL throughout my career and love it, though the cost can be prohibitive.
In my home setup, I’m leaning toward open-source databases like Postgres or MySQL. Postgres seems to be everyone’s favorite, so I’ll give it a try and write some articles about setting it up. Ultimately, the most important factors for me are backups, proper indexing, and monitoring (hello, Airflow!).
I’m also going to try and play with some cloud data warehouses. My background is in regulated healthcare data so this is will be something new for me.
For unstructured data like audio files or PDFs, I’ll leave that for another day.
3. Data Transformation & Modeling
This layer handles:
- Cleaning and integrating raw data into a structured format.
- Transforming data for analysis, creating aggregations and marts for better performance.
- Organizing data into logical models for tools like Power BI, reducing the complexity of DAX and Power Query.
I use DBT (Data Build Tool) for this. It simplifies creating materialized views and incremental tables, saving me from the nightmare of writing merge logic in stored procedures. Plus, DBT integrates with version control, keeping your models standardized and maintainable.
4. Analytics & Business Intelligence (BI)
This is where the magic happens—delivering insights from your data. Business users typically need:
- A data catalog to understand what’s available.
- Accessible raw data (data democratization).
- Analyses and alerts to drive decisions.
For analytics tools, Power BI is fantastic but comes with its challenges. For my home stack, I’m planning to explore free alternatives like Apache Superset, Metabase, and Grafana, starting with Grafana.
5. Monitoring, Quality Checks and Observability
You need to know when something breaks—failed pipelines, database errors, or backup issues. Email alerts are fine, but I also like push notifications and Slack alerts. I’m planning to set up Gotify for this.
6. Data Governance and Documentation
The Importance of Documentation in Data
Good documentation is essential. It’s the key to governance, collaboration, and not losing your mind when deadlines hit. The code itself is not the documentation, and while this is a pain point for many, it’s non-negotiable for me.
For my setup, I’ll start with BookStack to document configurations. It supports Markdown and keeps things organized, though I’m open to alternatives.
Data Governance Tools
Another area I want to delve into in this series is data governance tools. While these might primarily benefit data analysts or individuals with high data literacy, I believe it’s important to document our models comprehensively. This includes answering questions like:
- What are our models?
- Why were they created?
- Where does the data come from?
- How should the models be used?
- What purpose do they serve?
In my experience, failing to document these details leads to headaches. For example, I’ve worked with EHR systems whose data warehouses contained over 19,000 tables. Not all of them were actively used, but remembering how process X was reflected in model Y became a serious time drain. Proper documentation can save hours of frustration and improve productivity across teams.
Key Areas of Data Governance
Data governance encompasses several critical components:
- Discovery: Understanding what data exists and where it resides.
- Quality: Ensuring data is accurate, consistent, and reliable.
- Glossary: Defining and standardizing terms across the organization.
- Lineage: Tracking the journey of data from source to destination.
- Modeling: Structuring and documenting data models effectively.
Exploring Data Governance Tools
There are many tools aimed at tackling these challenges, as illustrated in this awesome data catalogs list. I’m particularly interested in trying out Open Data Discovery, as it takes an opinionated approach to documenting data models. My goal is to integrate a tool that not only organizes metadata but also enforces best practices for documenting models in a way that’s both scalable and useful.
Final Thoughts
Building a data stack is as much about choosing the right tools as it is about organizing them to work seamlessly together. This is my starting point, but I’m sure it will evolve as I dive deeper.
What tools are you using in your data stack? I’d love to hear your thoughts!